

The Design Problem ¶
In a centralized world, searching doesn’t involve too many difficult decisions on the part of the user. When typing into a search box, the user trusts that the service is giving them the results they’ve asked for. This usually involves algorithms to display information in a way that makes sense to the user — including filtering, ranking, and selecting information intelligently. For most services, the user has little-to-no choice on how this search and discovery is executed on their behalf, and if controls are offered, these options are usually buried within profile and platform settings.
In a decentralized world, users can choose which service is searching on their behalf to discover new information and users. New problems arise from this ability to choose their service, including:
- Whose data am I searching?
- Am I searching across the entire network, or just a subset of the network?
- Who can I ask for help if the search doesn’t work as intended?
- How did this content get in my search, and how can I see more or less of certain topics?
In a peer-to-peer application, you can only search for what you have downloaded, or what your known peers have downloaded. Similarly, in a federated context, search is only possible through your known server or federated server network. In both cases, if the network is very large, this decentralized search begins to surface problems in safety and performance.
The Design Solution ¶
Users need to obtain a basic understanding of the differences between search that is mediated by federation and search enabled by a central service. Pair with the Content Curators pattern.
Allow users to opt-in to search and discovery of content. For search, add indicators for scope (e.g., local vs global). For discovery, add indicators for filtering and curation. Allow users to opt-out of having their content searched through (e.g. locally vs globally).
Provide the ability for users to easily configure which servers to search. These considerations can be governed by the protocol or client. For example, the client can be ‘fat’ (e.g., download everything by default and search it all); ‘thin’ (e.g., download very little and call out to another server for search); or ‘gossipy’ (e.g., search only what my direct peers or peers of peers have downloaded).
Examples ¶
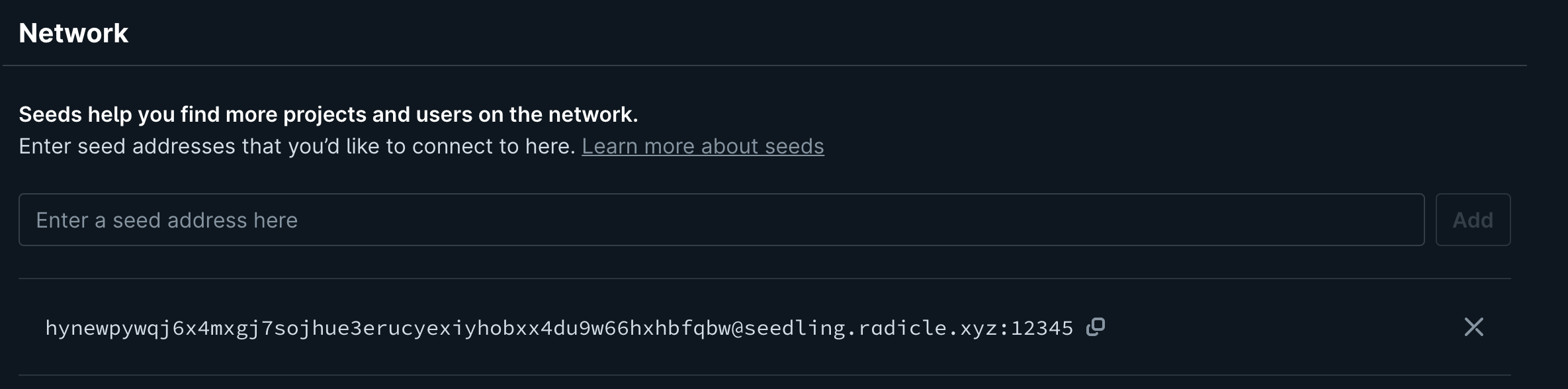 Discovery servers are called ‘Seeds’ in Radicle
Discovery servers are called ‘Seeds’ in Radicle ‘Pubs’ in Secure Scuttlebutt
‘Pubs’ in Secure ScuttlebuttWhy Choose Discovery Server? ¶
When your application is heavily enriched by the ability to search and discover new content (e.g., social networks).
Best Practice: How to Implement Discovery Server ¶
- Provide the possibilities to curate data and expand one’s network while staying local.
- If you are using a service for your search algorithm, transparently show the name of the service along with a way to contact those people (e.g., a git repository or website).
- Services should provide filters for well-known abusive, fraudulent, or spam content. This is critical to prevent a scenario where first-time users see a bombardment of irrelevant or harmful content.
Potential Problems with Discovery Server ¶
This can cause a dependency on particular services, re-centralizing the technical architecture and causing potential failures. To mitigate this, the protocol could allow for any peer to provide the search functions to another peer.
There is still a need to address the privacy concerns regarding search queries and end-to-end encrypted information. For example, in a pure peer-to-peer network, users’ search queries might encounter a risk if exposed to a wider network.
The Take Away ¶
Search is possible in a decentralized network, and can provide users better control over which algorithms and filters to use, opening space for a variety of discovery services that can be run by anybody.